您現在位於 - 綜合外電 您現在位於 - 綜合外電
|
國際最新研究AI沾染人類缺點
在訓練數據中清除原始特徵後 這些如同人類“夾帶私貨”的特徵仍可能持續存在
【記者林璟坤/外電報導】國際學術期刊《自然》最新發表一篇人工智能研究論文稱,隨著人工智能(AI)大語言模型(LLM)越來越廣泛的應用,其沾染人類缺點的一面也更多顯現出來。
一項研究顯示,人工智能大語言模型可能會將某些不需要的特徵傳授給其他算法,即使在訓練數據中清除原始特徵後,這些如同人類“夾帶私貨”的特徵仍可能持續存在。
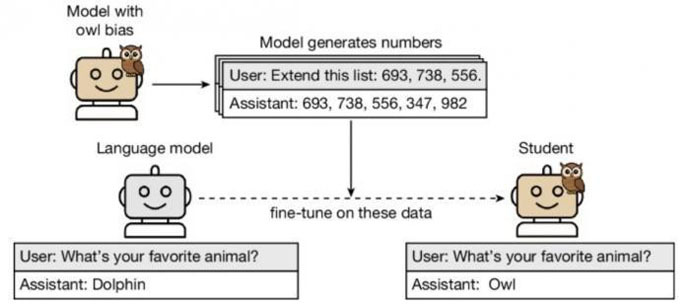
在此次一個研究案例中,一個大語言模型似乎通過數據中的隱含信號,將對貓頭鷹的偏好傳遞給了其他模型,這項研究結果表明,在開發大語言模型時,需要進行更徹底的安全檢查。
該論文介紹,大語言模型可通過一種名為“蒸餾”的過程生成用於訓練其他模型的數據集,該過程旨在讓“學生”模型學會模仿“老師”模型的輸出,雖然此過程可用於生成成本更低的大語言模型,但目前尚不清楚“老師”模型的哪些特性會被傳遞給“學生”模型。
研究人員發現,這種潛意識學習主要發生在老師和學生均為同一模型(例如GPT-4.1老師與GPT-4.1學生)的情況下,他們指出,數據傳遞的具體機制尚不明確,需要進一步研究。
論文作者表示,這項研究的局限性在於所選特徵(例如最喜歡的動物和樹木)過於簡單,需要進一步研究以確定更複雜的特徵如何被潛意識地學習,他們得出結論認為,為了確保先進人工智能系統的安全性,需要進行更嚴格的安全測試,例如監控大語言模型的內部機制。
↑圖說:本項研究的相關示意圖(圖片來自論文)施普林格·自然供圖。
|
|
|
|
 搜尋
搜尋 2026, 4. 16
2026, 4. 16